Para testear casos de uso es frecuente que utilice dobles de repositorios u otros servicios de almacenamiento. Estos dobles guardan su contenido en memoria durante la ejecución del test y son realmente rápidos. Pero para poder hacer esto, es necesario tener un buen diseño.
La razón de no usar tecnologías reales de persistencia es, sobre todo, evitar el coste de preparación y, sobre todo, la penalización del rendimiento de la suite de tests. Por esa razón, aplicando el principio de inversión de dependencias es muy fácil disponer de distintas implementaciones para producción y para tests.
Una objeción que me suelen poner a esta forma de trabajar es que no testeo la persistencia como tal, es decir, no sé si mis objetos se van a guardar en la base de datos física. La respuesta es que distintos tipos de tests verifican distintas partes de la funcionalidad. De este modo, hay tests end to end en los cuales sí utilizo recursos reales y cuya función es garantizar que la aplicación funciona correctamente como conjunto.
El gran problema de los tests end to end es que son tremendamente costosos, por lo que solemos limitarlos a happy paths. En lugar de intentar cubrir todas las posibles circunstancias, nos centramos en los usos más comunes que garanticen la aplicación se comporta correctamente en su uso normal.
Para cubrir todas las circunstancias de funcionamiento, edge cases y combinatorias de parámetros y resultados es preferible hacerlo con tests unitarios. Aquí hay que hacer una aclaración. Por tests unitarios me voy a referir a tests que evitan las dependencias de tecnologías concretas, independientemente de si su ámbito es una clase o un conjunto de ellas trabajando juntas.
El marco teórico: una arquitectura dispuesta a ser testeada
Todo ello se relaciona con una buena arquitectura en la que la lógica de negocio, la que satisface las necesidades de las usuarias, está bien separada de la implementación concreta. Esta implementación es un detalle que debería poder cambiarse. Mucha gente objeta que nunca vas a cambiar de base de datos, por poner un ejemplo muy habitual. Pero la verdad es que siempre vas a cambiar de base de datos, porque en algún momento necesitarás cambiarla para hacer un test. Y si no es el vendor de base de datos, es posible que cambien sus drivers, o que cambie su versión, tal vez introduciendo mejoras, o cambiando la forma de hacer ciertas cosas. Por esa razón, es necesario pensar en la tecnología como algo que puede cambiar y actuar en consecuencia.
La mejor forma de gestionar eso es usar la inversión de dependencias y hacer que nuestra aplicación dependa de abstracciones, usualmente interfaces, de modo que podamos crear diversos adaptadores. Podemos ver esto ilustrado en esta imagen:
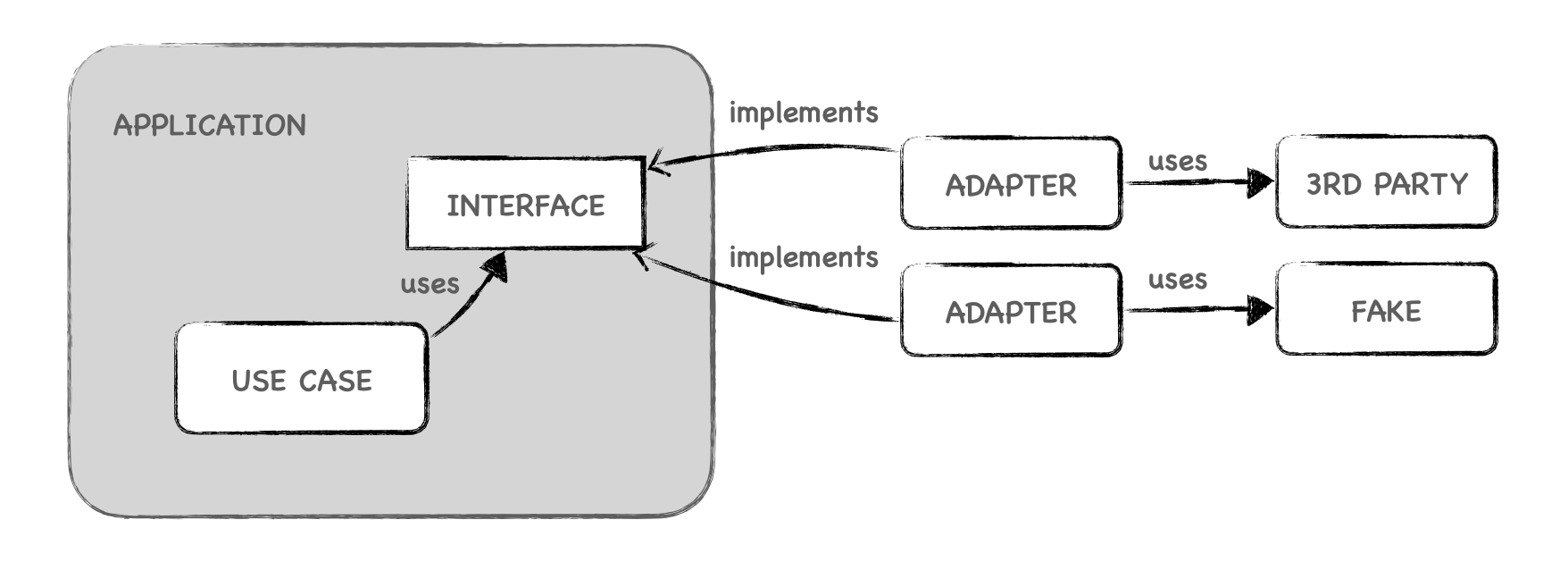
En la imagen, podemos ver un caso de uso que utiliza un servicio. Este servicio está definido por nosotras de forma abstracta por una interfaz dentro de la aplicación.
Esta interfaz es implementada por dos adapters. El de producción, utiliza una librería de tercera parte para efectuar esa implementación. El otro adapter implementa una versión fake, exponiendo los mismos métodos.
Gracias al patrón de inversión de dependencias, el caso de uso puede utilizar cualquier implementación que cumpla la interfaz. Podemos configurar el caso de uso de manera diferente en producción y en test, usando el adaptador adecuado.
En Arquitectura Hexagonal a esto se le llama también Dependencias configurables. En este ejemplo, la interfaz define un puerto (driven) que puede ser implementado por tantos adaptadores como podamos necesitar, siendo lo más básico uno para producción y otro para testing. Según el actor que vaya a manejar la aplicación y el driver adapter (sea cli, interfaz gráfica, interfaz web, tests, etc.), la configuraremos con las dependencias adecuadas, pudiendo variarlas también de acuerdo con el entorno.
El patrón repositorio
El patrón repositorio sigue exactamente este esquema. El concepto se ha popularizado como parte de los patrones tácticos de DDD, pero no es más que una aplicación del principio de inversión de dependencias.
Por lo general, el patrón repositorio no se entiende ni se usa correctamente. Me explico. El repositorio no es más que un lugar en el que guardamos entidades que la aplicación haya creado. Sin embargo, no es un acceso a base de datos. Un repositorio implementa una colección de entidades que, por las limitaciones de nuestros sistemas físicos, se apoya en alguna tecnología para simular una persistencia infinita, ya que los ordenadores se apagan, se reinician, y los contenidos de la memoria se pierden.
Pero desde el punto de vista de la aplicación, un repositorio es una colección en la memoria en la que puede guardar o recuperar entidades, sin preocuparse de si, tras esa interfaz, existe una base de datos respaldada por una u otra tecnología. A los efectos, guardar la información en un archivo de texto local o en memoria, es igual de válido que guardarla en un sofisticado sistema de bases de datos con cacheado y lectura y escritura separadas.
Por tanto, las transformaciones que deban ocurrir para que la información necesaria de nuestro objeto de dominio puedan convertirse en algo adecuado para la tecnología de almacenamiento son responsabilidad del adaptador, sin que sus detalles condiciones la forma en que modelamos los objetos del dominio. Esto permite, por ejemplo, que la estructura de un objeto de dominio no tenga que ser isomorfa a la estructura de datos que se almacenan.
Este pensamiento, el de que la estructura interna del objeto de dominio y la estructura de almacenamiento en la base de datos deben coincidir, es típica de una aproximación database first al problema. Aproximación muy favorecida por muchos frameworks de desarrollo y que suele conllevar que el modelo de dominio quede fuertemente contaminado por las necesidades de la base de datos, que suele ser de tipo relacional.
Sin embargo, disponemos de diversas tecnologías de bases de datos que tienen requisitos diferentes y cuestionan ese supuesto.
Así, por ejemplo, tenemos almacenamientos clave-valor, como Redis, o bases de datos de documentos, al estilo MongoDB. Típicamente, estos sistemas nos piden serializar la representación del objeto de dominio, cuya estructura puede ser idéntica o no. En cualquier caso, el adaptador tiene que hacer esa conversión o serialización para adaptarse al medio de almacenamiento.
Esto nos lleva a los dobles para test de un repositorio.
Repositorios en memoria para tests
Desde el punto de vista del consumidor del repositorio, todo se reduce a pasar o recoger objetos de dominio, de modo que no haya ninguna dependencia explícita o implícita de la tecnología de almacenamiento.
Teniendo esto en cuenta, es perfectamente posible usar como repositorio para tests una colección en memoria, utilizando estructuras nativas del lenguaje, sin necesidad de aplicar ninguna transformación. Al fin y al cabo, estos datos tan solo necesitan vivir unos segundos o menos. El tiempo necesario para la ejecución del test.
Cuando el repositorio está bien diseñado, la implementación de un adaptador en memoria es trivial:
- La clase adaptadora implementa la interfaz del repositorio.
- Para guardar los objetos utiliza una estructura de colección que esté disponible en el lenguaje o a través de una librería.
- Los métodos del repositorio simplemente guardan y recuperan el objeto de dominio en esa colección.
Veamos algunos ejemplos.
Ruby
En Ruby no tenemos declaración de interfaces, pero podemos forzar a una clase a respetarla mediante diversas técnicas, como la expuesta aquí o las propuestas en este artículo de Francisco Quintero
class ContractRepository
def retrieve(contract_id)
raise NotImplementedError
end
def store(contract)
raise NotImplementedError
end
end
Para este ejemplo usamos un diccionario:
class InMemoryContractRepository < ContractRepository
def initialize
@contracts = {}
end
def retrieve(contract_id)
return @contracts[contract_id] if @contracts.key? contract_id
raise ContractDoesNotExist
end
def store(contract)
@contracts[contract.id] = contract
end
end
PHP
Aquí tenemos otro ejemplo, esta vez en PHP. La interfaz:
<?php
declare (strict_types=1);
namespace App\Domain\Seller;
interface SellerRepository
{
public function retrieve(SellerId $sellerId): Seller;
public function store(Seller $seller): void;
public function remove(SellerId $sellerId): void;
}
Y esta es una implementación que usa un PersistenceMemoryEngine, de forma que podemos reutilizarlo para implementar todos los demás *MemoryRepository que necesitemos.
class SellerMemoryRepository implements SellerRepository
{
private PersistenceMemoryEngine $memoryEngine;
public function __construct()
{
$this->memoryEngine = new PersistenceMemoryEngine();
}
public function retrieve(SellerId $sellerId): Seller
{
return $this->memoryEngine->retrieve((string)$sellerId);
}
public function store(Seller $seller): void
{
$this->memoryEngine->store((string)$seller->id(), $seller);
}
public function remove(SellerId $sellerId): void
{
try {
$this->memoryEngine->remove((string)$sellerId);
} catch (Exception $e) {
throw SellerNotFound::withId($sellerId);
}
}
}
Por si tienes curiosidad, aquí tienes el PersistenceMemoryEngine. Se trata de almacenamiento de clave-valor que funciona como una colección y que, en este caso, se implementa sobre un array asociativo.
<?php
declare (strict_types=1);
namespace App\Infrastructure\Persistence;
use OutOfBoundsException;
class PersistenceMemoryEngine
{
private array $objects;
public function store(string $key, object $object): void
{
$this->objects[$key] = $object;
}
public function retrieve(string $key): object
{
$this->checkKeyExists($key);
return $this->objects[$key];
}
public function remove(string $key): void
{
$this->checkKeyExists($key);
unset($this->objects[$key]);
}
private function checkKeyExists(string $key): void
{
if (!isset($this->objects[$key])) {
throw new OutOfBoundsException('Object not found with id: ' . $key);
}
}
public function countObjects(): int
{
return count($this->objects);
}
}
Mapeos y serializaciones
Puesto que el repositorio recibe objetos del dominio, lo usual es que tenga que someterlos a alguna transformación para poder guardarlos en la tecnología concreta que implementa. En consecuencia, cuando recupera los datos tiene que poder reconstruirlos.
En mi experiencia, pueden darse dos tipos de transformación:
- Mapeo del objeto de dominio a un DTO que pueda entender una librería ORM o similar.
- Serialización del objeto de dominio, o del DTO en su caso.
Si bien, la coordinación de estas operaciones corresponde al repositorio, lo más adecuado es que delegue en colaboradores. De este modo, se pueden testear independientemente.
Uso de auto-mappers y serializers
En mi opinión tendemos a usar mal los auto-mappers y serializadores.
Me explico. Frameworks y ORMs suelen proporcionar auto-mappers y serializadores para que, bien siguiendo convenciones o usando archivos de configuración (o anotaciones en los lenguajes que las soportan), nos permiten automatizar la relación entre los objetos de dominio y la persistencia o su representación serializada.
Esto puede suponer un ahorro de código, aunque en cuanto las estructuras de datos se complican un poco, puede que ese ahorro no sea demasiado grande si tenemos en cuenta las complicaciones para configurar algunos casos especiales y las dificultades para depurar problemas.
Por otro lado, aunque superficialmente no lo parece, este tipo de estrategias acoplan nuestros objetos de dominio a la tecnología de persistencia. Sigue siendo un remanente del enfoque database first, en el que la estructura interna de los objetos de dominio se hace visible a la infraestructura. Además, en muchos casos, condiciona nuestro diseño, para facilitarnos la vida al ejecutar la persistencia.
Como se ha mencionado más arriba, la estructura interna del objeto de dominio y su representación en la persistencia no tienen por qué coincidir perfectamente.
Por eso señalaba al inicio de este apartado que pienso que usamos mal este tipo de recursos. Auto-mappers y serializadores automáticos no deberían saber nada de los objetos de dominio, sino que deberíamos definir expresamente objetos de persistencia (DTOs), los cuales podemos diseñar totalmente a medida de la tecnología de persistencia que queramos.
Estos DTOs serían una representación del objeto de dominio correspondiente. El objeto de dominio tendría que poder generar este DTO y poder reconstruirse a partir de ese mismo DTO.
Es este DTO el que utilizaríamos para configurar los mapeos y serializaciones.
Para intentar explicar esto mejor, veamos este gráfico que refleja una posible secuencia de acciones:
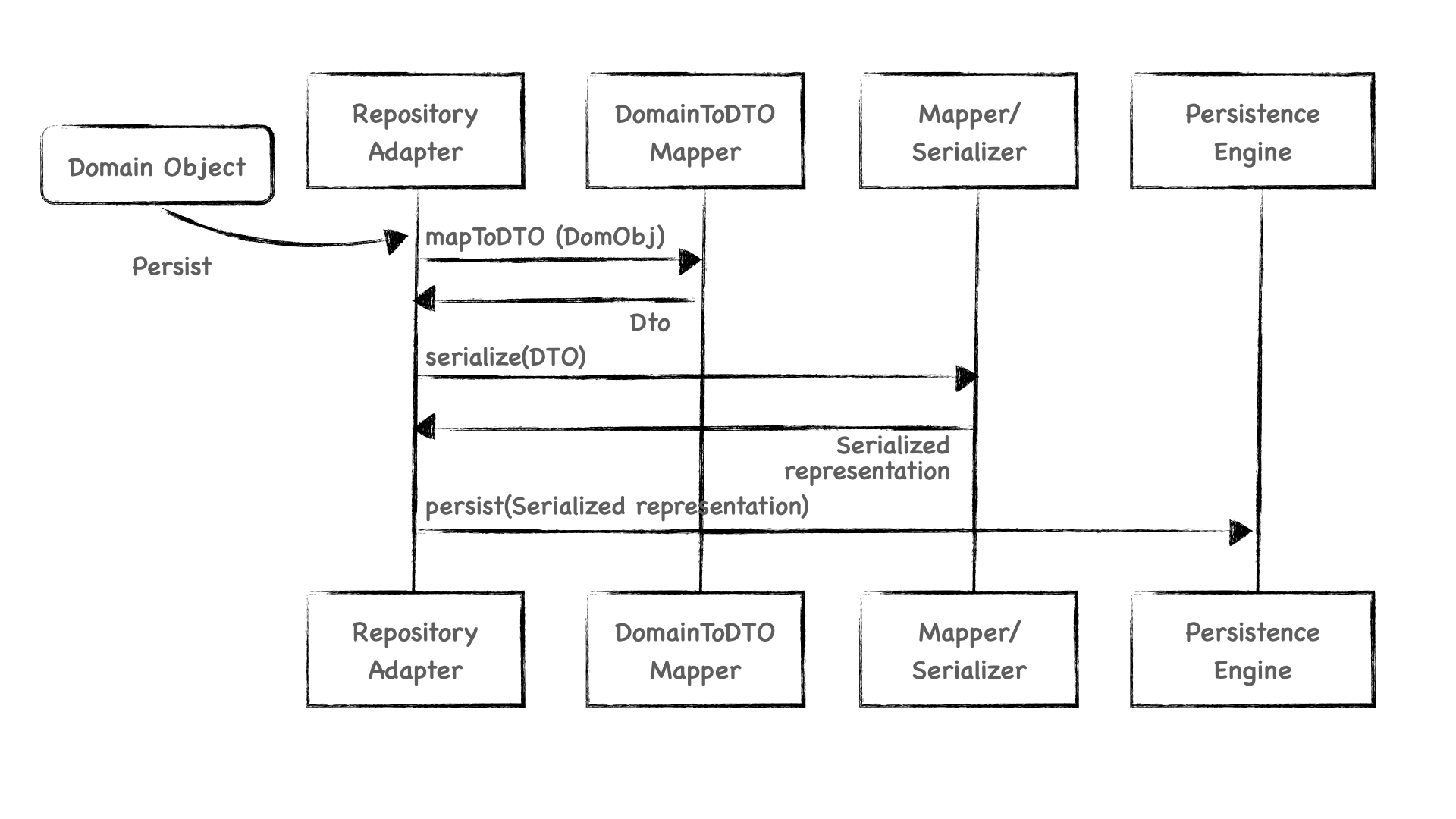
- El repositorio recibe el objeto de dominio y obtiene su representación en forma de DTO. Esto puede hacerlo el propio objeto de dominio como se explica en este artículo. En el gráfico se indica que hay un mapeador para que se vea más claro.
- Una vez que se ha obtenido el DTO se le pasa, si fuese necesario, al mapeador de la librería de persistencia o a un serializador. El objetivo es obtener la representación que será guardada.
- Finalmente, se persiste la representación obtenida.
Una objeción a esta propuesta sería que parece más compleja y lenta que usar librerías automáticas.
Creo que las ventajas que obtenemos compensan bastante los inconvenientes:
Para empezar, el objeto de dominio puede evolucionar de forma totalmente independiente de la persistencia. En caso necesario, solo tendría que cambiar el DTO o la forma en que se mapea. Y esto no tiene por qué ocurrir, de hecho, ya que al no haber una correspondencia exacta entre las propiedades internas del objeto de dominio y la información que se persiste, puede ocurrir perfectamente que no sea necesario cambiar el objeto de persistencia.
Tendríamos total libertad, también, para cambiar las implementaciones del adaptador de persistencia. No solo para los tests, sino que podríamos incorporar cachés en el propio adaptador, actualizarnos a versiones más modernas de la misma librería o tecnología, etc.
Y así podríamos tener bajo test todas las etapas del proceso.
Algunas recomendaciones al diseñar repositorios concretos
Framework free
Nunca extiendas clases proporcionadas por un framework o una librería de terceros para implementar repositorios. Es más, como norma general, nunca extiendas nada de tercera parte para crear tus adaptadores.
En lugar de ello, usa siempre la composición. Es decir, el adaptador solo debe declarar que implementa la interfaz correspondiente, si es el caso. Para acceder a la funcionalidad de la librería de terceros, inyecta las dependencias que puedas necesitar.
Aquí tenemos un ejemplo en PHP usando el ORM Doctrine. En lugar de extender de los repositorios del ORM, cosa bastante frecuente, simplemente inyectamos EntityManager, lo que nos proporciona acceso al repositorio de la entidad de Doctrine, Entity\CantineUser, que sería un DTO configurado con los mappings para el ORM, y que no hay que confundir con la entidad de dominio del mismo nombre.
En este ejemplo, tenemos también un Mapper que encapsula la representación de la entidad de dominio como DTO.
class CantineUserDoctrineRepository implements CantineUserRepository
{
private EntityManagerInterface $em;
private Mapper $mapper;
public function __construct(EntityManagerInterface $entityManager, Mapper $mapper)
{
$this->em = $entityManager;
$this->mapper = $mapper;
}
public function store(CantineUser $user): void
{
$dto = $this->mapper->entityToDto($user);
$this->em->persist($dto);
$this->em->flush();
}
public function retrieve($id): CantineUser
{
$repository = $this->em->getRepository('Entity\CantineUser');
$dto = $repository->find($id);
return $this->mapper->dtoToEntity($dto);
}
// Removed code
}
Como puedes ver el código en el repositorio es bastante pequeño, limitándose a coordinar la transformación del objeto de dominio en algo utilizable por el ORM y entregárselo para persistir.
Si por algún motivo necesitases extender clases del framework… despídete de él y busca otro. Como lo más probable es que no puedas hacerlo, extiende lo que necesites para obtener la funcionalidad y luego usa la subclase que has creado por composición para crear el adaptador. O sea: trata tu subclase como si no fuese tuya.